Why Your Best AI Users Cost the Most: What AI Product Pricing Actually Decides
On AI products, cost scales with engagement. Your heaviest users are your most expensive to serve. Here is the one number to compute before you pick a pricing model.
The complaint surfaces in almost every AI product pricing conversation I have with founders: "I keep losing money on my best users." They say it with a kind of confused frustration, as if the product is misfiring somewhere they cannot quite locate.
It is not misfiring. The pricing structure is what broke.
AI product gross margins reached 52% in 2026, up from 41% in 2024, according to ICONIQ's State of AI report, which surveyed roughly 300 software executives. [1] Real progress. But the baseline still being compared against is traditional SaaS: 80 to 90% gross margins. The gap reflects a structural difference in how cost behaves on these products, not just a technology cost problem waiting to be optimized away. [3]
The structural fact is this: on an AI product, cost scales with usage. A heavy user who loves your product is the most expensive user to serve. The SaaS instinct to reward engagement with flat, unlimited pricing quietly builds a loss machine. This piece explains the inversion, shows what it looked like for three companies that encountered it at scale, and offers one diagnostic to think through before you pick an architecture.
Pricing is one of those decisions where building the wrong structure faster does not feel wrong at first. The revenue comes in, the users are happy, and then the unit economics arrive.
The Inversion SaaS Founders Keep Missing
In SaaS, serving one more user costs almost nothing. You built the feature; the marginal cost of the next customer is compute and support at the edges. That is the business model the 80 to 90% gross margin benchmark reflects. [3]
AI products are a different cost architecture entirely. Every request runs inference. A user who makes ten requests costs roughly ten times what a user who makes one request costs. This is not a temporary inefficiency waiting for model pricing to fall (though it will fall). It is the fundamental shape of the cost curve. Engagement and cost are correlated. That correlation is what the SaaS playbook was never designed to handle.
The ICONIQ data puts a number on the gap. AI product gross margins at 52%, up from 41% two years earlier. [1] That improvement is real, and it reflects genuine work: model routing, caching, prompt compression, inference optimization. The founders reaching 52% have generally figured out their cost architecture. The ones stuck closer to 41% often have a pricing structure problem as much as a cost problem. Those two categories get conflated, and fixing the wrong one takes longer and costs more than it should.
Model costs will keep falling. API prices across frontier providers have dropped significantly over the past two years, and that direction is not reversing. But usage grows faster. The net direction for most AI products is not back toward the SaaS margin baseline. It is toward a new equilibrium somewhere below it, and where that equilibrium lands depends on how well you matched your pricing architecture to your actual cost curve at launch.
The inversion is the premise the rest of this argument builds on: your heaviest users cost you the most, and flat pricing transfers all of that cost to you.
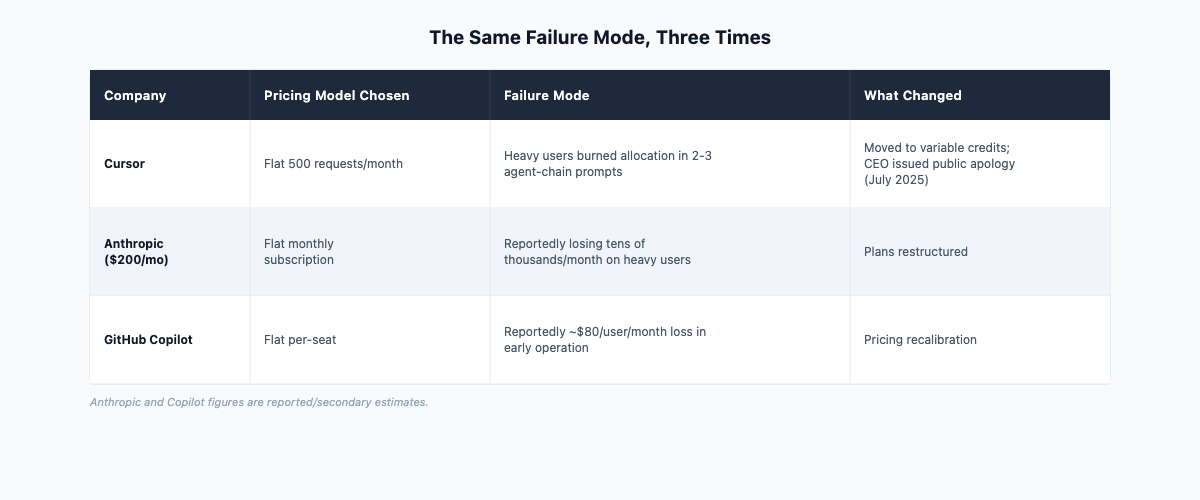
The Same Failure Mode, Three Times
Three companies encountered this at meaningful scale in 2025. The pattern is worth looking at specifically, because it is the same across products with very different use cases.
Cursor's original pricing gave users a flat allotment of 500 requests. As reported by Aakash Gupta, some users were burning through that entire allocation in two or three prompts, because each prompt was spawning a chain of agent calls. [2] Cursor moved to variable credits. The reaction was significant enough that the CEO issued a public apology on July 4, 2025. The structural change was right; the transition and framing created the backlash. Users did not understand what "one request" actually cost in agent terms, because the abstraction had hidden it.
Anthropic reportedly acknowledged losing tens of thousands of dollars per month on heavy users of its original $200/month Claude plan. [2] The math is not complicated: if your median user costs $30 to serve and your 95th-percentile user costs $400 to serve, a flat $200 plan is wrong in both directions at once. You are overcharging the light users and subsidizing the heavy ones. Neither group is priced correctly.
GitHub Copilot reportedly lost approximately $80 per user per month in early operation. [3] That figure is a secondary estimate from industry analysis, not an audited number, and should be read as a directional claim. But it is consistent with what the other cases show: flat-rate pricing on a product where heavy usage is rewarded concentrates losses among your most engaged users.
None of these companies made a calculation error. They chose a pricing architecture before they knew their own usage distribution. The users arrived, usage concentrated at the tail, and the cost curve showed up. The failure, as with many AI product problems, was upstream of where the symptoms appeared.
Before You Pick a Model, Answer One Question
Most pricing advice skips directly to the model comparison: usage-based versus subscription versus credits. Each has obvious trade-offs, and the articles that catalog them are genuinely useful. But the catalog is not the decision. Before any model makes sense to compare, there is one number worth computing.
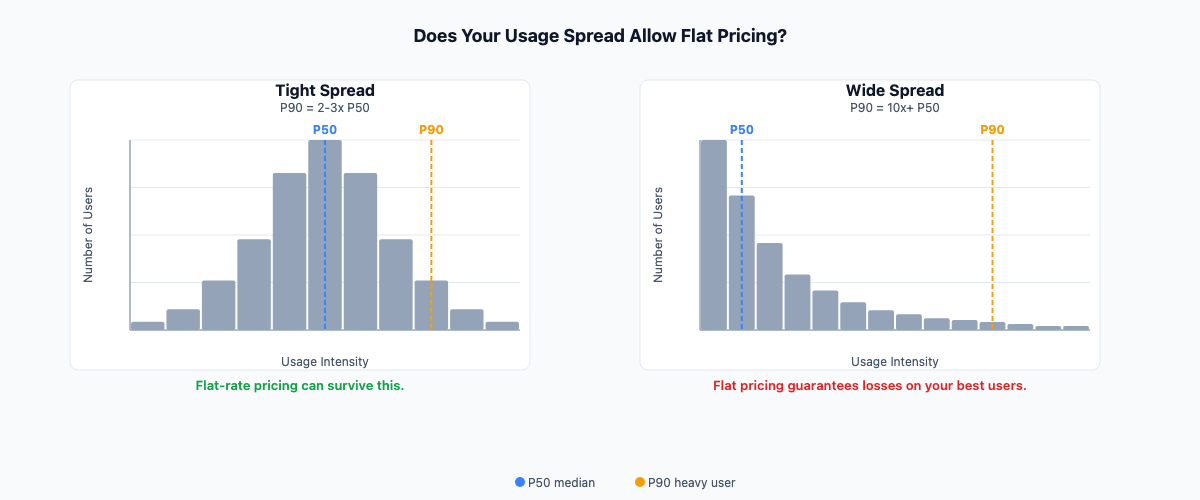
What does your 90th-percentile user cost you to serve, versus your median user?
I would call this the spread question, and the P50-vs-P90 framing is my own. It is not an industry standard or a cited benchmark. It is the question I would ask before signing off on any pricing architecture.
Here is the logic. If your P90 user costs roughly two to three times your P50 user, your usage distribution is tight. A flat-rate model with an appropriate buffer can survive that spread. You will lose some margin on the very heaviest users, but the distribution is predictable enough to price defensibly.
If your P90 user costs ten times or more than your P50 user, your distribution is wide. Flat pricing in that scenario is a structural guarantee of losses on your most engaged customers. The flat rate gets set near the median to stay competitive. The heavy users cost you five to ten times what they pay. That is where the margin goes.
The spread matters more than the average cost. A product where the average inference cost per session is $0.50 could still be deeply unprofitable on a flat subscription if the P90 is $5.00 and those users are the product's best-reviewed, most retained, most vocal advocates. The average obscures the distribution; the distribution is what the pricing model has to survive.
For a new product, without live usage data, the best proxy is your benchmark heavy user. Who is the most intense plausible user of what you are building? For a coding assistant, maybe a developer running agent loops across a full working day. For a customer support tool, maybe a team handling five hundred tickets a week. Model the inference cost for that scenario, compare it to the median session your product is designed for, and compute the ratio. That number tells you which pricing structure to start from.
If you genuinely cannot form an estimate, the right move is not to default to the model everyone else uses. It is to design an early beta structure that lets you observe the distribution before a public pricing page goes live.
How Six AI Pricing Models Map to Your Cost Curve
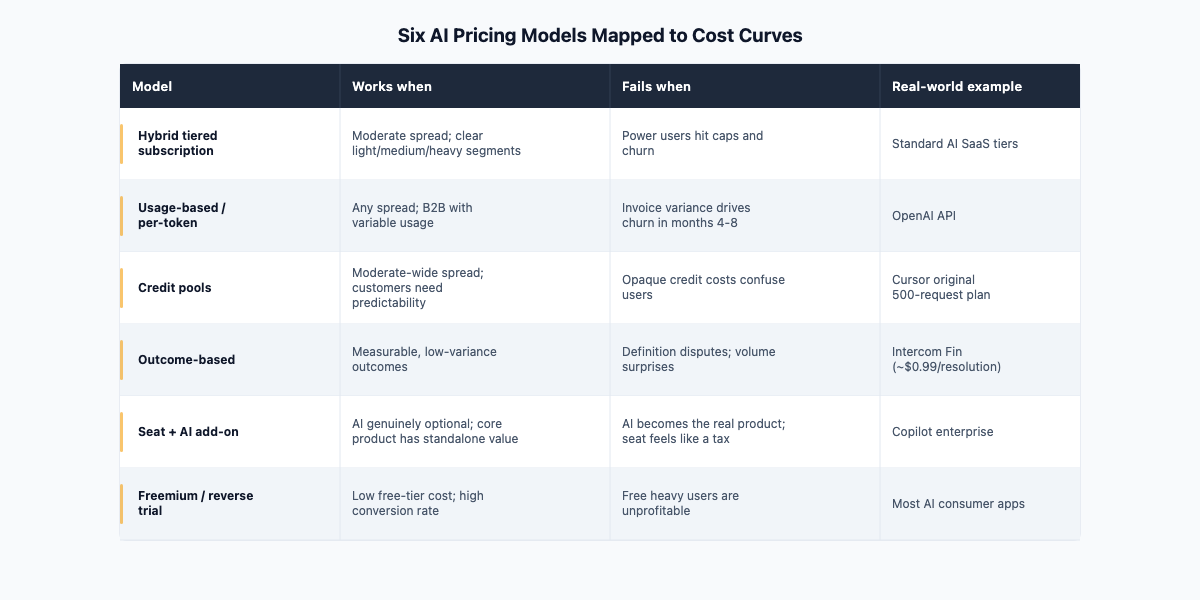
Aakash Gupta's taxonomy of AI pricing models is the clearest map I have found: six architectures, each with a different relationship to the spread question. [2] The point is not to pick one from the list. It is to know which failure mode you are buying when you choose.
Hybrid tiered subscription. Fixed tiers with usage caps at each level. Works when the spread is moderate and users can be segmented meaningfully into light, medium, and heavy. Fails when power users consistently hit caps and churn, or when cap thresholds need constant revision as usage patterns evolve.
Usage-based / per-token. Customers pay for what they use. Works for any spread because cost and revenue scale together. Fails on predictability: customers cannot budget for a variable bill, and churn in months four through eight is common once invoice variance collides with quarterly budget reviews.
Credit pools. Users buy a block of credits and draw from it. Predictable for the customer (they know what they bought), cost-aligned for you (usage stops when credits run out). Fails when the credit abstraction is opaque, or when users hit the credit wall at a moment that feels arbitrary. Cursor's original 500-request system was effectively this model, and the failure mode was that users did not understand what a single "request" actually cost in agent chains.
Outcome-based. Price per resolved ticket, per completed task, per measurable result. Intercom Fin charges approximately $0.99 per resolution, which Gupta's analysis estimates could reach roughly $17,820 per month for a team handling 30,000 conversations. [2] That figure is an illustrative calculation, not an audited revenue number, but the model is real. Fails when the definition of an "outcome" is contested, when customers dispute whether results count, or when volume variance creates unpredictability on the customer's side.
Seat plus AI add-on. Base seat licensing with the AI capability available as an optional paid extension. Works when the core product has standalone value and AI usage is genuinely optional. Fails when AI becomes the reason customers buy, which makes the add-on feel like the product and the seat feel like a licensing tax.
Freemium or reverse trial. Free tier with conversion to paid. Works for distribution when the AI cost at the free tier is manageable and conversion rates are high. Fails when free-tier users are heavy users and the cost of serving them cannot be recovered from the conversion rate.
Save this table for the next time the pricing debate starts in your team.
The Counterargument Worth Taking Seriously
Once you understand the cost curve, usage-based pricing can feel like the obvious answer. It scales with cost, it aligns incentive, it does not subsidize heavy users at the expense of your margin. The logic is clean.
But there is a real problem on the other side, and it would be wrong to dismiss it.
Predictability matters for adoption. Founders report roughly 47% subscriber churn between months four and eight on AI tools, with unpredictable billing cited as one of the factors. [5] That figure comes from a community discussion, not a controlled study, so treat it as a directional signal rather than a verified number. It reflects something real nonetheless: customers who cannot forecast their monthly bill will sometimes choose a competitor with a flat price, even if the flat price is slightly higher on average. Budget certainty is a feature.
This is not just customer-empathy. It is commercial reality. The total cost of churn (lost revenue, reacquisition cost, support load) can exceed the cost of subsidizing heavy users on a flat model, depending on the lifetime value dynamics of the specific product. Outcome-based pricing is theoretically the most aligned model, but most teams end up spending more time disputing what counts as a resolution than they spend on the pricing model itself. Industry analysis points to hybrid routing and structured tiers as the practical answer for most AI products. [4]
The counterargument does not lead to "therefore stay flat." It leads to: know your spread, then decide how much predictability you can afford to offer at that spread. A credit-pool model or a hybrid tier with a defined usage buffer can give customers enough predictability to budget while routing cost variance back to actual usage. That is not a compromise between two bad options. It is what a well-designed pricing architecture actually looks like.
The reason Cursor, Copilot, and Anthropic had to recalibrate their pricing is not that they got the math wrong. They chose an architecture before they knew their cost curve. That sequence is the mistake.
Pricing architecture is a launch decision. What it decides is not revenue per seat. It decides whether the margin survives the users who love the product most. The founders who find that out at $50k MRR have a harder conversation than the ones who estimated the spread before the pricing page went live.
One number before any model: what does your P90 user cost to serve, versus your P50? That ratio tells you more about which structure fits than any benchmark, any competitor reference, or any pricing article, including this one.
If you are mid-pricing-debate, send this to the person you are arguing with.
TL;DR
On AI products, cost scales with engagement. A flat subscription that rewards power users quietly subsidizes your most expensive usage. Before picking a pricing model, compute your P50-vs-P90 cost ratio. A tight spread (P90 = 2–3x P50) can support flat-rate pricing with a buffer. A wide spread (P90 = 10x+) almost always requires usage-based, credit-pool, or hybrid architecture. Three major AI products recalibrated their pricing in 2025 because they chose the architecture before they knew the curve.
References
- ICONIQ Growth. "State of AI 2026," via SaaStr. "ICONIQ's Latest State of AI Report: The 10 Most Important Data Points for SaaS Founders." https://www.saastr.com/iconiqs-latest-state-of-ai-report-the-10-most-important-data-points-for-saas-founders . Accessed 2026-06-16.
- Gupta, Aakash. "How to Price AI Products." https://www.news.aakashg.com/p/how-to-price-ai-products . Accessed 2026-06-16.
- HireFraction. "AI Is Killing SaaS Margins — Outcome-Based Pricing Is How You Get Them Back." https://www.hirefraction.com/blog/ai-is-killing-saas-margins-outcome-based-pricing-is-how-you-get-them-back/ . Accessed 2026-06-16.
- SaaSMag. "The AI COGS Problem: Why SaaS Gross Margins Are Compressing in 2026." https://www.saasmag.com/ai-cogs-saas-gross-margin-compression/ . Accessed 2026-06-16.
- Indie Hackers. "The uncomfortable truth about AI tool pricing in 2026." https://www.indiehackers.com/post/the-uncomfortable-truth-about-ai-tool-pricing-in-2026-92944b6a4d . Accessed 2026-06-16.