You're Debugging the Wrong Thing: AI Agent Failures Start Before the First Prompt
Developers blame the model when their AI coding agent reverts fixes, hallucinates features, or loses context. The data says the bottleneck is further upstream than that.
Last Tuesday, your AI coding agent rewrote the same authentication utility it fixed the week before. Different prompt, different session. Same bug, same file, same line. You spent the next forty minutes re-explaining why the session middleware was off-limits, re-scoping the /api/v1/ boundary, re-establishing what "done" looked like for that ticket. Then you got something close enough to ship and moved on.
The natural conclusion: the model isn't smart enough yet.
It's the wrong conclusion.
The bottleneck isn't computation. The smartest model available can't execute an ambiguous instruction more reliably than a junior developer who reads it charitably. And like a junior developer who never asks clarifying questions, your agent will fill the gaps. Just not with what you had in mind. The culprit isn't in the model weights. It's in the document you wrote before you ran the first prompt.
Your AI coding agent isn't confused. It's doing exactly what you asked
Agent "mistakes" look like model failures from a distance. Up close, they're almost always faithful execution of an under-specified instruction.
Consider two ways to scope the same feature:
- "Add authentication to the API."
- "Add JWT-based authentication to
/api/v1/routes only. The existing session middleware in/middleware/session.tsmust not be modified. New tokens expire in 24 hours. No refresh-token flow in this iteration."
The first instruction is sincere. It describes a goal. But it leaves open which endpoints, which mechanism, whether existing code is in bounds, what the expiry window should be, and whether adjacent features are in scope. The agent will resolve each of those open questions, and you won't know how until it shows you.
The pattern is visible in community discussions too. In a Hacker News thread titled "I don't think AI will make your processes go faster," a top commenter made the point plainly: clear specifications have always been the bottleneck in software delivery, and AI tools accelerate iteration without improving specification quality. [\[3\]](https://news.ycombinator.com/item?id=48168221) The acceleration is real. The bottleneck just surfaces faster now.
The frustrating part is that agents often get things right, which hides the structural problem. When the output is good, it's usually because the instructions were clear enough to narrow the decision space to a single reasonable path. When the output is wrong, the instructions almost always had two or three plausible readings.
This isn't a new failure mode
The wall most developers are running into has been in the data since 1981.
Barry Boehm calculated, in Software Engineering Economics, published forty-five years ago, that a requirements defect costs up to 100x more to fix after release than at the specification stage. [\[5\]](https://www.worldcat.org/title/software-engineering-economics/oclc/7172194) That figure has been cited so often it fades into background noise. But run it against your agent loop: every session spent re-explaining the same context is a downstream payment on a requirements defect you introduced before the first prompt.
The scale in traditional software development is striking. Meta Group found that 60 to 80 percent of project failures trace directly to poor requirements. [\[1\]](https://www.allstacks.com/blog/specification-quality-ai-product-management) PMI reported, in its 2021 Pulse of the Profession survey, that 40 percent of software project failures are caused by poor requirements. [\[1\]](https://www.allstacks.com/blog/specification-quality-ai-product-management)
Those figures describe a world of human developers: people who ask clarifying questions, infer team context, and default to familiar patterns when instructions are incomplete.

Run those numbers against the AI agent loop and the conclusion draws itself: AI didn't create the requirements problem. It removed the slack that used to absorb it.
AI removed the buffer, not the bug
That Boehm figure deserves more than a passing mention. Human software teams worked from ambiguous specs for decades and still shipped things, sometimes successfully. They improvised the missing decisions, asked questions in standups, built shared context over months of proximity. Ambiguity got absorbed before it ever reached the code. A thin spec was survivable because the people executing it had enough context to fill the gaps.
An AI coding agent working from the same thin spec, in a fresh context window with no ambient team history, has none of that. It executes the instruction as written, resolves the gaps according to its training distribution, and produces something internally coherent but wrong for your intent. The model performed correctly with the instructions it was given.
The developers who've gone deep with AI coding tools are discovering this the hard way. One, writing on Hacker News about their LLM development workflow, described spending "sometimes even up to half an hour" in a discovery phase before writing a line of code, talking with the model until they were confident it understood what they wanted. [\[4\]](https://news.ycombinator.com/item?id=47394022) That's not an inefficiency. That's someone building the spec incrementally before execution, because skipping that step costs more.
Better prompts help, but only to a point. A well-crafted prompt surfaces missing decisions before the agent runs into them. When the same ambiguity recurs across three sprints and four agent sessions, the fix isn't to keep writing better prompts. The fix is to write it down once, in a form the agent can reference every time.
What a working spec actually contains (the data says six things)
Fortunately, someone counted.
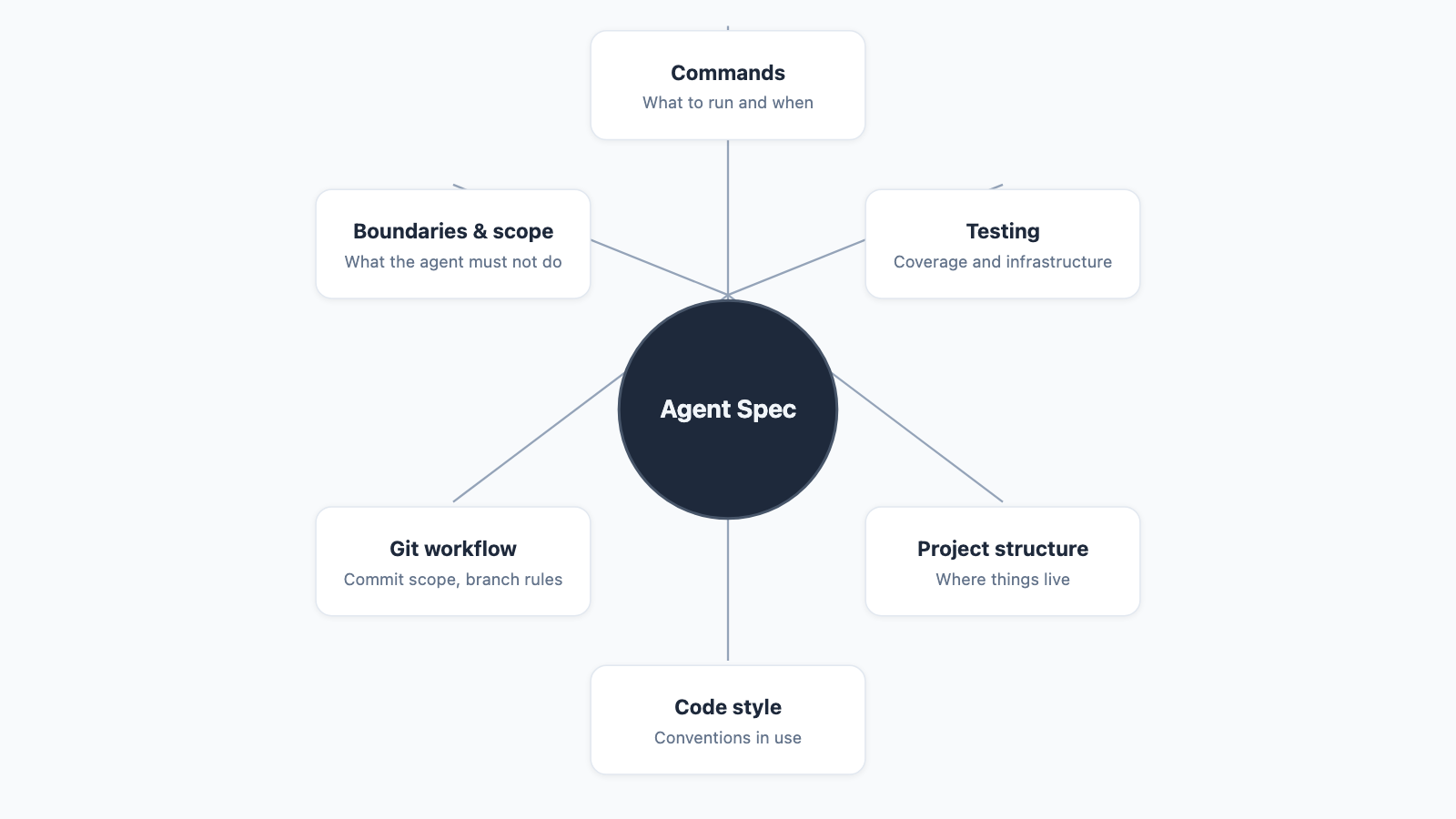
Addy Osmani analysed more than 2,500 agent configuration files from GitHub and found that the specs producing reliable agent behaviour consistently addressed six areas: commands, testing, project structure, code style, git workflow, and boundaries and scope. [\[2\]](https://addyosmani.com/blog/good-spec/) "Most agent files fail," Osmani noted, "because they're too vague."
Each area eliminates a category of decision the agent would otherwise make from training priors alone:
- Commands: what to run and when, removing guesswork around build scripts and test runners.
- Testing: what coverage means and what infrastructure exists, preventing tests for frameworks you don't use.
- Project structure: where things live, blocking duplication of utilities already in
/lib. - Code style: conventions in use, keeping the agent from introducing patterns inconsistent with the codebase.
- Git workflow: commit scope and branch rules, ensuring untouchable files stay untouched.
- Boundaries and scope: what the agent is not supposed to do, which is the constraint most specs omit entirely.
The last item is where most agents go wrong in practice. Negative constraints ("do not modify session middleware," "authentication is out of scope for this ticket," "this file is read-only") are obvious to the developer writing the prompt and invisible to the model executing it. They have to be written down.
For a practical starting point on converting vague intent into an inspectable, structured brief your team can review, that work begins before you open an agent session.
You are not a bad prompter. You are not using the wrong model. You are hitting a 40-year-old wall that every software team hit before AI coding agents existed, the wall that forms when the people executing work don't share the context of the people assigning it.
What changed is that AI coding agents made that wall immediate and unavoidable. Human developers absorbed the ambiguity quietly, filling in gaps with judgment built from months of context and a thousand small conversations. Agents don't have that. They execute the specification exactly as written, and the gaps in the specification become errors in the output.
The fix was never a better model. It was always a better spec.
Send this to a teammate who's been debugging the wrong thing.
References
- Allstacks. "Specification Quality & AI Product Management." https://www.allstacks.com/blog/specification-quality-ai-product-management. Accessed 2026-06-11. (Cites Meta Group 60-80% and PMI 40% figures.)
- Osmani, Addy. "How to write a good spec for AI agents." https://addyosmani.com/blog/good-spec/. Accessed 2026-06-11.
- Hacker News. "I don't think AI will make your processes go faster." https://news.ycombinator.com/item?id=48168221. Accessed 2026-06-11.
- Hacker News. "How I write software with LLMs." https://news.ycombinator.com/item?id=47394022. Accessed 2026-06-11.
- Boehm, Barry W. Software Engineering Economics. Prentice-Hall, 1981. https://www.worldcat.org/title/software-engineering-economics/oclc/7172194.