The Interactive Spec Your Engineer, Reviewer, and AI Agent Can All Read
Your spec now has three readers: a human reviewer, an engineer scoping the work, and an AI coding agent executing it literally. The format most teams still ship was built for one of them.
Your team runs the same spec through an AI coding agent and an engineer. Both build something. Neither built the same thing. Three days of reconciliation follow. The spec was never wrong. That is the problem.
Most teams land here and conclude the model is not smart enough yet. That conclusion is wrong, and the data suggests it has been wrong for a while. The bottleneck is not computation. It is the document you handed off before you opened the first prompt. That document needs to be an interactive spec.
The spec now has three readers: a human who reviews it for approval, an engineer who scopes the work from it, and an AI coding agent that executes it literally. The artifact most teams still ship, a written requirements document plus a Figma file, was designed for one of them.
Den Delimarsky, writing for the GitHub blog on the Spec Kit release, put the code-side version of this plainly: "We're moving from 'code is the source of truth' to 'intent is the source of truth.' With AI the specification becomes the source of truth and determines what gets built." [3] That shift does not just change what the agent needs from the spec. It changes what the spec is.
The spec has three readers now. They need three different things.
A human reviewer reads a spec to decide whether to approve work for implementation. They are good at filling in gaps, because they have team context, product history, and the ability to ask a follow-up question. A written requirements document is well-suited to this reader: it gives context and intent, and the reviewer supplies what's missing from ambient knowledge.
An engineer reads a spec to scope the work: what states exist, what the boundaries are, what counts as done. Engineers need precision on behavior, not on vision. They will ask about edge cases if the spec doesn't supply them, but the asking costs time: an async question to a PM, a wait, a clarification, a re-read. The Figma file helps them see the happy path, but it does not tell them what to do when a user cancels from an unsaved state, or what the loading skeleton should look like on a slow connection.
An AI coding agent reads a spec literally. It has no ambient product context, no team history, no ability to flag ambiguity before acting on it. It executes what the spec says, resolves every gap according to its training distribution, and produces something internally coherent. When it builds the wrong thing, it is usually because the spec had two or three plausible readings, and the agent chose one without asking.
This is not a failure of model capability. It is a structural mismatch between what the artifact was built to communicate and who is now reading it. Why AI coding agents fail is almost always traceable to this: the spec was written for the reviewer, handed to an engineer who could ask questions, and is now being handed to an agent that cannot.
The failure mode is not dramatic. It looks like the agent building a validation error in a different state than intended, or implementing a button that submits when it should save a draft, or creating a duplicate utility that already exists three directories over. All of these are faithful executions of an under-specified document. The spec was correct. The spec was just not complete enough for this reader.
That is not a gap you close by writing more prose. It is a structural problem, and two separate disciplines recently published their answers to it.
Two industries converged on the same answer from opposite ends.
Starting around 2025, two separate communities began publishing their solutions to this problem. They did not coordinate. They arrived at nearly the same artifact from opposite directions.
From the design side, Figma launched an MCP server that streams design context directly into AI coding tools. The announcement describes what this means in practice: "MCP servers like Figma's MCP server add onto this by bringing outside context from other tools like Figma into that workflow, so your code doesn't just match the fingerprint of your codebase, but that of your design, too." [1] Components, variables, styles, layout structure, React and Tailwind representations: the design artifact is now machine-readable by agents. The Figma file is no longer a picture the engineer looks at. It is structured context the agent reads.
At Config 2025, Figma introduced Figma Make, a prompt-to-code tool that turns written descriptions or existing designs into working interactive prototypes and runnable apps. [2] The prototype is no longer a static mockup waiting to be translated. It is an executable artifact in its own right.
From the writing side of the design discipline, intent prototyping emerged as a separate answer to the same problem. Yegor Gilyov, writing in Smashing Magazine, describes the artifact this way: "The engineering team doesn't need to reverse-engineer a black box or become 'code archaeologists' to guess at the designer's vision, as they receive not only a live prototype but also a clearly documented design intent behind it." [4] The interactive prototype plus documented intent, as a single handoff artifact, not separated across a Confluence page and a Figma link.
From the code side, GitHub's Spec Kit established spec-driven development: the spec as the executable source of truth that AI agents work from, through a pipeline of Specify, Plan, Tasks, and Implement. [3] Not a vague prompt, not a wall of prose, but a structured artifact with intent encoded into it, which the agent can reference at every phase of the build.
The design community was solving the designer-to-engineer communication gap. The developer community was solving the spec-to-agent execution gap. Both hit the same constraint: structured intent, attached to an interactive artifact, is the minimum for reliable execution by any reader.
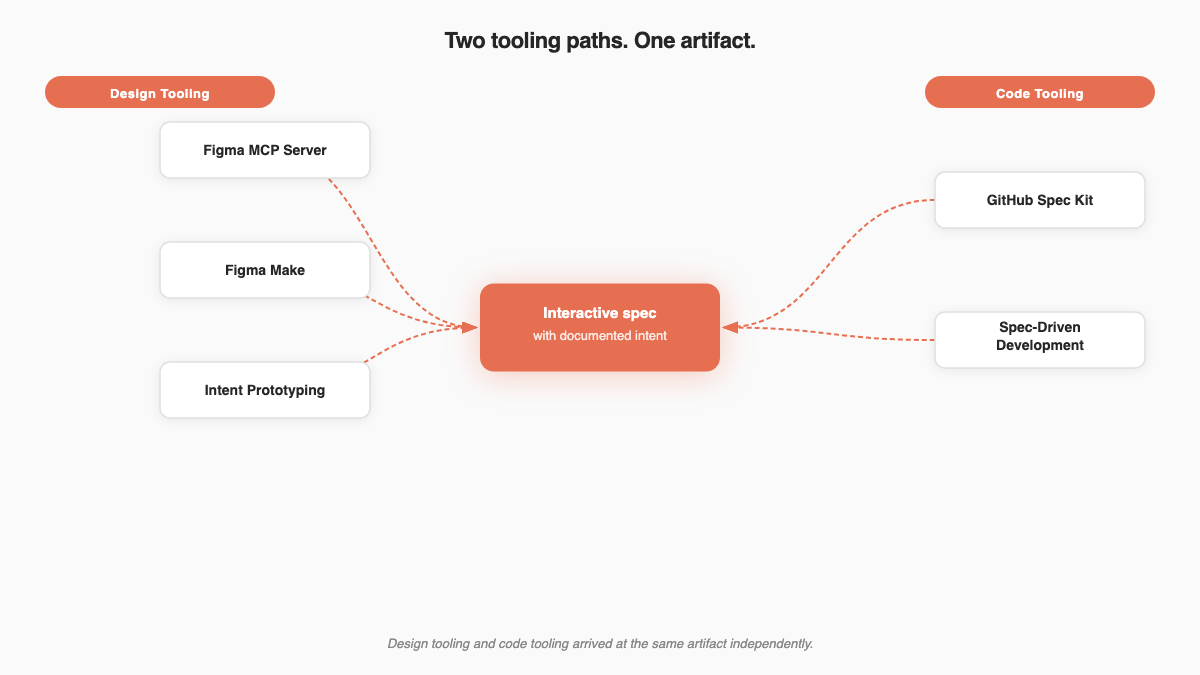
Design tooling and code tooling arrived at the same artifact independently. Most product teams have not noticed yet.
The three layers of an interactive spec
The word "interactive" tends to get applied to anything with a click. That is not the definition that matters here.
An interactive spec, in the sense that serves all three readers, has three distinct layers. Each layer serves a different audience.
The first layer is the interactive prototype: not a static mockup, but a clickable, stateful representation of the product surface. It shows what happens on each interaction, what the error state looks like, what the component does when disabled. This is the layer the AI coding agent can render and verify behavior against. Figma's MCP server makes this layer machine-readable; Figma Make makes it executable. [1] [2]
The second layer is structured requirements: explicit acceptance criteria attached to states and components, not just "the button submits the form" but the edge cases, the disabled states, the error handling, the negative constraints. An AI coding agent operating from layer one alone will implement behavior for states the prototype did not show. Layer two closes those gaps.
The third layer is documented intent: the reasoning behind the pattern. Why this interaction model was chosen, what it is optimizing for, what is deliberately out of scope. This is what Gilyov calls "design intent." [4] Without it, the engineer has to reverse-engineer the decision from the artifact, and the AI agent has no basis for choosing between two equally plausible implementations.
A written PRD is layer two in prose form. A Figma file is layer one without layer two or three. Neither is the artifact.
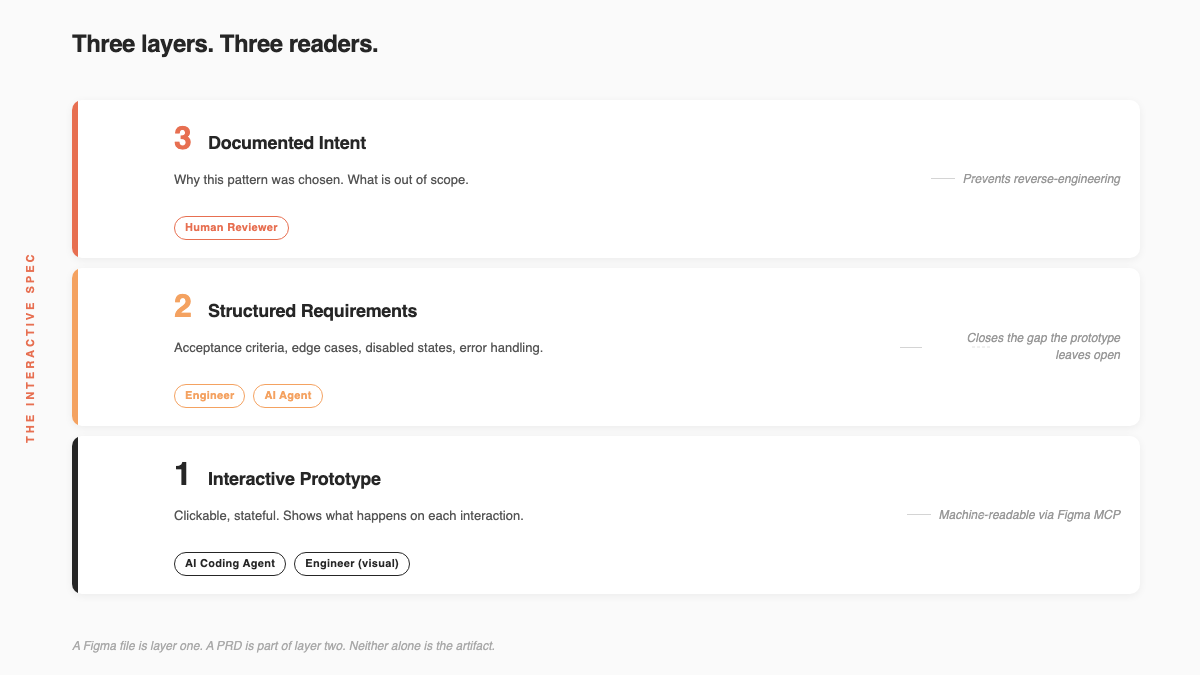
The three layers of an interactive spec. A Figma file is layer one. A PRD is part of layer two. Neither alone is the artifact.
Where most static handoffs quietly break
The reason teams do not notice the gap during review is that the human reviewer is the reader the current artifact was built for. They fill in the missing pieces with context they already carry, and the review passes without surfacing the gaps.
The engineer discovers the gaps when they start scoping. They ask about the loading state for a slow network. They ask whether the validation fires on blur or submit. They ask what happens if the backend returns a partial response. These are reasonable questions, and a good team answers them. But each question is an async round-trip: a message, a wait, a response, a re-read. Multiply by five edge cases across three components and you have a week's worth of clarification cycles baked into a spec that looked complete.
The AI coding agent discovers the gaps when it builds the thing. It does not ask questions first. It implements what the spec implies, resolves the missing decisions from its training distribution, and shows you the result. Sometimes it guesses right. When it guesses wrong, the output is confident and internally consistent, which means review often passes before anyone notices.
The reconciliation scenario from the introduction is a direct product of this: the spec was reviewed by a human who filled the gaps with context, executed by an agent that did not have that context, and re-executed by an engineer who had a different mental model than either. The three days spent reconciling were not a failure of any individual; they were the cost of shipping a layer-one artifact and calling it a handoff.
That cost is manageable when the agent runs once on a task. It compounds when the agent has standing access to the spec and reads it on every push.
When the agent has standing access, the spec becomes infrastructure
Most product teams are thinking about AI coding agents as a workflow step: give the agent a task, review the output, merge or revise. Under that model, a spec written for occasional one-off agent sessions can absorb gaps. The human is in the loop on every run and catches the deviations.
That model is already changing. Figma's MCP server streams design context into Cursor, VS Code Copilot, Windsurf, and Claude Code on every session, automatically. [1] The agent is not handed the design as part of a task prompt. It reads the live design system as a persistent background context, every time it opens a file.
As AI agents become embedded operational infrastructure across industries, as TechRadar documented in April 2026, [5] the pattern of standing, persistent access to specification systems is becoming standard rather than exceptional. Organizations are testing and deploying agentic AI at scale, and governance frameworks are lagging significantly behind adoption. [6]
The governance gap matters because of what standing access changes. An agent that reads a spec once and executes is a workflow step. An agent that has standing MCP access to the spec system and re-reads on every push is a team member. And team members need a different quality of spec than a one-time tool does.
A spec written for periodic human review can have gaps, because the human reviewer fills them contextually. A spec that an agent reads on every push cannot have gaps at the structural level, because the agent will execute them differently every time: once one way, once another, depending on what else changed in the context window. The output diverges not because the agent changed, but because the spec was never complete enough to produce a single consistent interpretation.
This is what makes the interactive spec a governance question and not just a handoff question. When the spec becomes the persistent source of truth that agents read, continuously, it has to be the kind of artifact that produces consistent interpretation. The MCP infrastructure that gives agents standing access to design and product systems is already in place. Most teams have not updated their spec format to match.
The convergence already happened. Figma and GitHub did not plan this together. They were solving different problems for different audiences and arrived at the same minimum: a clickable, stateful prototype with structured requirements and documented intent attached.
Most product teams are still behind that convergence. They are shipping a written doc and a Figma link and calling it a handoff. That was sufficient when the only reader was human, because human readers fill gaps. The artifact that works for three readers, an interactive spec with all three layers present, is not a specific tool or platform. It is a quality bar. Naming it is the first step to applying it.
Send this to your design lead.
For a practical look at what a complete handoff package contains once the spec is in place, see what the Friday-to-Monday handoff actually delivers.
References
- Figma. "Introducing our Dev Mode MCP server: Bringing Figma into your workflow." https://www.figma.com/blog/introducing-figma-mcp-server/ . Published 2025-06-04. Accessed 2026-06-24.
- Figma. "Config 2025 Press Release: Figma Make and new product announcements." https://www.figma.com/blog/config-2025-press-release/ . Published 2025-05-07. Accessed 2026-06-24.
- Delimarsky, Den. "Spec-driven development with AI: Get started with a new open source toolkit." GitHub Blog. https://github.blog/ai-and-ml/generative-ai/spec-driven-development-with-ai-get-started-with-a-new-open-source-toolkit/ . Published 2025-09-02. Accessed 2026-06-24.
- Gilyov, Yegor. "Intent Prototyping: A Practical Guide To Building With Clarity (Part 2)." Smashing Magazine. https://www.smashingmagazine.com/2025/10/intent-prototyping-practical-guide-building-clarity/ . Published 2025-10-03. Accessed 2026-06-24.
- Daugherty, Michael. "2026: The year enterprise AI finally gets to work." TechRadar. https://www.techradar.com/pro/2026-the-year-enterprise-ai-finally-gets-to-work . Published 2026-04-03. Accessed 2026-06-24.
- TechRadar. "Navigating the rise of agentic AI in 2026." https://www.techradar.com/pro/navigating-the-rise-of-agentic-ai-in-2026 . Accessed 2026-06-24.